Close X

1772349844.jpg
1773384609.jpg
1770373830.jpg
1772598586.jpg
1770951441.jpg
1771836788.jpg
1773721891.jpg
1772595178.jpg
HPE Alletra Storage MP X10000 แพลตฟอร์มสตอเรจสำหรับข้อมูล และงาน AI Analytics
ข้อมูลขององค์กรกำลังเติบโตทั้ง “ปริมาณ” และ “ความซับซ้อน” ไม่ว่าจะเป็นไฟล์จำนวนมาก, ข้อมูลจากระบบธุรกิจ, logs, sensor/IoT ไปจนถึงชุดข้อมูลสำหรับ AI/ML ทำให้สตอเรจแบบเดิมที่ขยายยาก ดูแลยาก และเริ่มเป็นคอขวด ไม่ตอบโจทย์อีกต่อไป

HPE Alletra Storage MP X10000 ถูกวางตำแหน่งเป็นแพลตฟอร์มสตอเรจสำหรับงานข้อมูลสมัยใหม่ ที่เน้น การขยายแบบ scale-out, การใช้งานแบบ cloud-like experience, และการรองรับเวิร์กโหลดที่ต้องการ throughput สูง เช่น Analytics และ AI pipeline ช่วยให้องค์กรวาง “data platform” ที่เติบโตไปพร้อมธุรกิจได้จริง
ทำไมองค์กรยุคนี้ต้องการสตอเรจที่ “ขยายได้” มากกว่าเดิม
ปัญหาที่พบได้บ่อยเมื่อข้อมูลโตขึ้น ได้แก่
• เพิ่มความจุแล้วระบบไม่ได้แรงขึ้นตาม งานอ่าน/เขียนจำนวนมากเริ่มช้า
• ขยายระบบแต่ละรอบต้อง downtime/ย้ายข้อมูล/เพิ่มความซับซ้อน
• เวิร์กโหลดสมัยใหม่ (เช่น analytics/AI) ต้องการอัตราการรับส่งข้อมูลสูงและต่อเนื่อง
• ทีม IT ต้องบริหารระบบให้ “เหมือนคลาวด์” คือทำงานง่าย มองเห็นภาพรวม และคาดการณ์ได้
แนวทางแบบ scale-out จึงกลายเป็นคำตอบสำคัญ เพราะสามารถเพิ่มทรัพยากรเมื่อจำเป็นได้เป็นขั้น ๆ ไม่ต้องรื้อระบบทั้งชุด
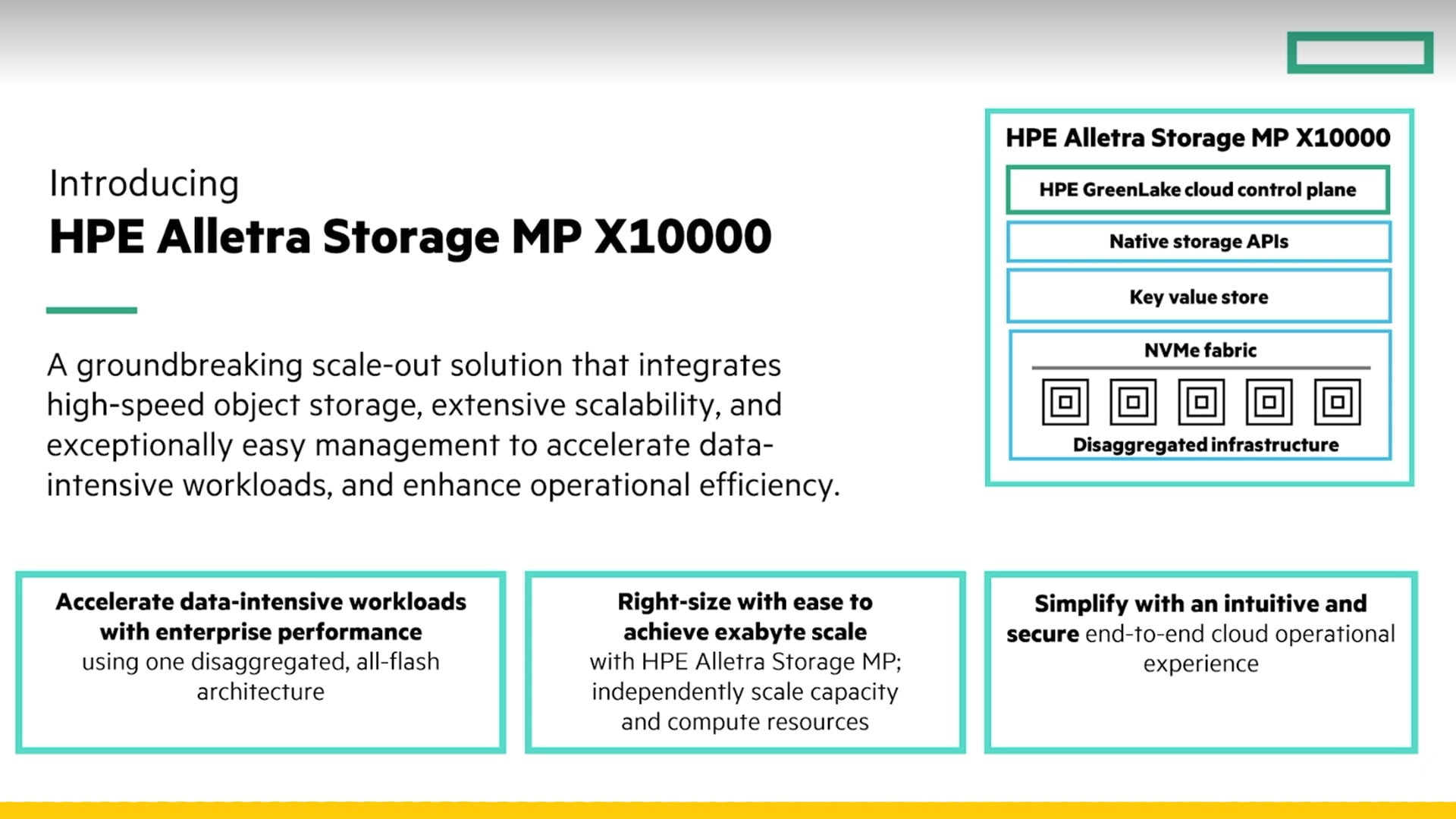
HPE Alletra Storage MP X10000 คือแพลตฟอร์มสตอเรจที่ออกแบบมาเพื่อรองรับข้อมูลและเวิร์กโหลดที่มีความต้องการสูง โดยมีแนวคิดหลักคือ
• Scale-out ได้: เพิ่มขีดความสามารถตามการเติบโตของข้อมูลและการใช้งาน
• รองรับงานข้อมูลสมัยใหม่: เหมาะกับ workload ที่ต้อง “ไหลข้อมูล” จำนวนมาก เช่น analytics, data processing, AI/ML pipeline
• การบริหารจัดการแบบ Cloud Operations: ลดภาระงานดูแลระบบ และทำให้การดำเนินงานเป็นมาตรฐานมากขึ้น
สรุปง่าย ๆ: ถ้าองค์กรต้องสร้าง “แพลตฟอร์มข้อมูล” ที่ใช้ร่วมกันหลายทีม หลายแอป และโตขึ้นเรื่อย ๆ X10000 ถูกออกแบบมาเพื่อโจทย์นี้โดยตรง

จุดเด่นที่องค์กรจะได้จาก Alletra Storage MP X10000
1). สเกลระบบให้โตตามข้อมูลได้จริง
แทนที่จะเจอปัญหา “ดิสก์เพิ่มแต่ระบบยังช้า” หรือ “ต้องย้ายระบบเมื่อโตเกิน” แนวทาง scale-out ช่วยให้ขยายทั้งความจุและสมรรถนะได้อย่างเป็นขั้นเป็นตอน เหมาะกับองค์กรที่ข้อมูลโตต่อเนื่องทุกเดือน
2). เหมาะกับงาน Analytics และ AI pipeline
งานประเภทนี้มักไม่ได้ต้องการแค่ IOPS แต่ต้องการ throughput และการไหลของข้อมูล (data movement) ที่ดี เช่น การอ่านชุดข้อมูลขนาดใหญ่ การประมวลผลซ้ำ ๆ การป้อนข้อมูลให้ GPU/Compute หรือการทำ feature engineering ดังนั้นแพลตฟอร์มที่ออกแบบมารองรับงาน data-intensive จะช่วยให้ pipeline ทำงานได้ต่อเนื่องและเสถียรขึ้น
3). ลดความซับซ้อนในการบริหารจัดการ (Cloud-like)
องค์กรจำนวนมากต้องดูแลทั้ง on-prem และ cloud พร้อมกัน ความสามารถด้านการบริหารจัดการแบบ cloud operations ช่วยทำให้
• มองเห็นสถานะระบบได้ง่ายขึ้น
• วางมาตรฐานการใช้งาน/การขยายระบบได้ชัด
• ลดงาน manual ที่เสี่ยงผิดพลาด
4). เป็นฐานสำหรับ Data Services และ Data Protection ที่ทันสมัย
เมื่อองค์กรมี “แพลตฟอร์มข้อมูล” ที่แข็งแรง การต่อยอดไปสู่บริการด้านข้อมูล เช่น การปกป้องข้อมูล (backup/replication) และการบริหารวงจรข้อมูล จะทำได้มีประสิทธิภาพขึ้น โดยเฉพาะองค์กรที่ต้องการให้การสำรองข้อมูลไม่กลายเป็นคอขวดของระบบ

Use Cases ที่พบบ่อย
• Enterprise Data Platform: รวมข้อมูลหลายแผนก/หลายระบบบนแพลตฟอร์มที่ขยายได้
• Analytics / BI / Reporting: อ่านข้อมูลจำนวนมากพร้อมกัน ลดเวลารอคิวประมวลผล
• AI/ML Data Pipeline: เตรียมข้อมูลและป้อนข้อมูลให้ระบบประมวลผลได้ต่อเนื่อง
• Large unstructured data: ไฟล์จำนวนมาก ภาพ วิดีโอ logs และข้อมูลที่โตเร็ว
Checklist ก่อนเริ่มโครงการ
เพื่อให้เลือกสเปกและออกแบบได้ตรง แนะนำให้ประเมินก่อนว่า
1. เวิร์กโหลดหลักเป็นแบบไหน: เน้น throughput หรือเน้น latency/IOPS
2. ข้อมูลโตเฉลี่ยต่อเดือน/ปีเท่าไร และต้องการเผื่อการเติบโตกี่ปี
3. มีช่วง peak ที่ระบบถูกใช้งานหนักเมื่อไร (เช่น ช่วง ETL/Training)
4. ต้องการผูกกับ data protection/backup/DR แบบใด และมีเป้าหมาย RPO/RTO เท่าไร
5. โครงสร้าง network ปัจจุบันรองรับการไหลข้อมูลระดับที่ต้องการหรือไม่

บริการ QuickServ: ออกแบบ–ติดตั้ง–ทดสอบ ให้เหมาะกับงานจริง
QuickServ สามารถช่วยองค์กรวางโซลูชันบน HPE Alletra Storage MP X10000 ได้แบบครบวงจร ตั้งแต่
• ประเมินเวิร์กโหลดและหา “คอขวด” ของระบบเดิม
• ออกแบบสถาปัตยกรรมให้สเกลได้ตามการเติบโต
• ทำ PoC/Benchmark ตามงานจริง (analytics/AI/backup window)
• ติดตั้ง ย้ายข้อมูล และดูแลหลังใช้งาน (ตามรูปแบบบริการที่ลูกค้าต้องการ)
คำถามที่พบบ่อย (FAQ)
Q1: HPE Alletra Storage MP X10000 เหมาะกับใคร?
A: องค์กรที่มีข้อมูลเติบโตเร็วและมีเวิร์กโหลดแบบ data-intensive เช่น analytics, AI/ML pipeline, data platform รวมถึงงานไฟล์จำนวนมาก (unstructured data)
Q2: จุดเด่นของสตอเรจแบบ Scale-out คืออะไร?
A: ขยายระบบได้เป็นขั้น ๆ ตามการเติบโต เพิ่มทั้งความจุและสมรรถนะได้ยืดหยุ่น ลดการย้ายระบบหรือการอัปเกรดครั้งใหญ่
Q3: ถ้าองค์กรทำ AI/Analytics ทำไมสตอเรจถึงสำคัญ?
A: เพราะงานเหล่านี้ต้องการ throughput ต่อเนื่องและการไหลของข้อมูลที่ดี สตอเรจที่รองรับ data movement ได้มีประสิทธิภาพช่วยให้ pipeline ทำงานเร็วและเสถียรขึ้น
Q4: X10000 ต่างจากสตอเรจแบบเดิม (Scale-up) อย่างไร?
A: แนวคิดหลักคือการเพิ่มความสามารถด้วยการเพิ่มโหนด/โมดูล (scale-out) ทำให้รองรับการเติบโตและการเปลี่ยนแปลงของ workload ได้ดีกว่า และวางแผนขยายได้เป็นขั้นตอน
Q5: เหมาะกับงานไฟล์หรือข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data) หรือไม่?
A: เหมาะ โดยเฉพาะกรณีไฟล์จำนวนมาก เช่น media, logs, dataset สำหรับ AI/analytics และข้อมูลที่ต้องเก็บและใช้งานระยะยาว
Q6: จะรู้ได้อย่างไรว่าคอขวดอยู่ที่ Storage หรือ Network/Compute?
A: ต้องประเมินแบบ end-to-end เช่น throughput ที่ใช้งานจริง, ความเร็วเครือข่าย, ภาระ CPU/ระบบตัวกลาง และรูปแบบการเข้าถึงข้อมูลของแอป ก่อนสรุปสาเหตุและแนวทางแก้
Q7: ต้องเตรียมข้อมูลอะไรบ้างเพื่อออกแบบและ Sizing ระบบ?
A: ปริมาณข้อมูลปัจจุบันและอัตราการเติบโต, รูปแบบงานอ่าน/เขียน, ช่วงเวลาที่โหลดสูงสุด, เป้าหมาย performance และข้อกำหนดด้านการเก็บรักษาข้อมูล (retention/RPO/RTO หากเกี่ยวกับ DR)
Q8: QuickServ ช่วยอะไรได้บ้างในการเริ่มใช้งาน HPE Alletra Storage MP X10000?
A: ช่วยประเมิน workload, ออกแบบสถาปัตยกรรม, ทำ PoC/benchmark, ติดตั้ง/ย้ายข้อมูล และดูแลหลังใช้งานตามรูปแบบบริการที่ต้องการ



























































 Server
Server
 Hyper converged
Hyper converged
 Storage
Storage
 UPS
UPS
 Networking
Networking
 PC
PC
 All in one
All in one
 Notebook
Notebook
 Monitor
Monitor
 Printer
Printer
 Hosting
Hosting
 Google cloud
Google cloud
 AWS
AWS
 Huawei cloud
Huawei cloud
 SSL
SSL